
Optimiser les INSERT multiples (dans Oracle)
2012-03-08 #sql
Pour contrôler l'intégrité de certaines données, j'ai eu besoin de ramener une partie du contenu d'une grosse table clients d'une base de donnée DB2 dans une base Oracle. Je sais qu'il existe SQL*Loader mais c'est pas encore cette fois que je vais m'y remettre.
Une commande INSERT par ligne à traiter
Pour commencer, j'ai testé sur un sous-ensemble de données et j'ai tenté de faire ça au plus simple. Tellement simple que je me suis contenté de générer et d'exécuter une requête INSERT par ligne à insérer.
INSERT INTO MaTable (Colonne1, Colonne2, Colonne3) VALUES ('Un_1', 'Deux_1', 'Trois_1');
puis
INSERT INTO MaTable (Colonne1, Colonne2, Colonne3) VALUES ('Un_2', 'Deux_2', 'Trois_2');
puis
INSERT INTO MaTable (Colonne1, Colonne2, Colonne3) VALUES ('Un_3', 'Deux_3', 'Trois_3');
etc...
=> 12,07 secondes pour insérer 4579 lignes (soit 379 requêtes à la secondes).
Des commandes INSERT groupées dans un BEGIN / END
Plutôt que de faire un connexion.Execute() pour chaque ligne, j'ai regroupé les commandes INSERT à l'intérieur d'une expression BEGIN ... INSERT (un peu comme dans une procédure stockée) de façon à ne soliciter le serveur que pour un seul connexion.Execute().
BEGIN
INSERT INTO MaTable (Colonne1, Colonne2, Colonne3) VALUES ('Un_1', 'Deux_1', 'Trois_1');
INSERT INTO MaTable (Colonne1, Colonne2, Colonne3) VALUES ('Un_2', 'Deux_2', 'Trois_2');
INSERT INTO MaTable (Colonne1, Colonne2, Colonne3) VALUES ('Un_3', 'Deux_3', 'Trois_3');
etc...
END;
=> 6,37 secondes pour insérer 4579 lignes => déjà 2 fois plus rapide.
Note : Sous Dapper (et ADO.NET en général je suppose), Oracle ne supporte pas la présence de retours à la ligne dans la commande SQL : on obtient une erreur @@PLS-00103: Encountered the symbol "" when expecting one of the following@.
Pour résoudre ça, il suffit de ne pas faire de retour à la ligne quand on génère la grosse requête :
BEGIN INSERT INTO MaTable (...) VALUES (...); INTO MaTable (...) VALUES (...); ...; END;
Une commande INSERT à partir de plusieurs SELECT
Cette fois, au lieu de faire 1 accès au serveur pour malgré tout lui faire faire plusieurs INSERT, j'ai encore plus optimisé en lui envoyant une seule requête INSERT. Pour ça, j'ai transformé les "INSERT ... VALUES ..." en "INSERT ... SELECT FROM ..." :)
INSERT INTO MaTable (Colonne1, Colonne2, Colonne3)
SELECT ('Un_1', 'Deux_1', 'Trois_1') FROM DUAL
UNION SELECT ('Un_2', 'Deux_2', 'Trois_2') FROM DUAL
UNION SELECT ('Un_3', 'Deux_3', 'Trois_3') FROM DUAL
etc...
=> 2,84 secondes pour insérer 4579 lignes (soit 1612 requêtes à la seconde) => 4 fois plus rapide.
Résultat des courses
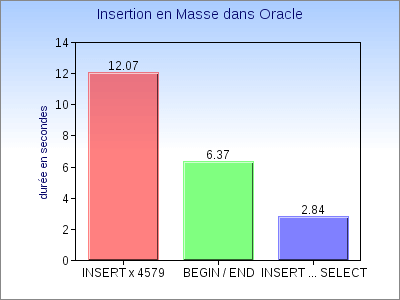
Ça valait quand même le coup de faire quelques essais, parce qu'au final, je suis passé de 379 insertions à la seconde à plus de 1600 ! Et comme j'ai près de 300.000 lignes à traiter, ça prendra dans les 3 minutes et pas 1/4 d'heure.
Mise en oeuvre
Dans la pratique, je copie l'intégralité des données par bloc de 500 clients pour éviter de saturer la mémoire :
public int SaveClients(IEnumerable<Client> clients)
{
var sql = @"UNION SELECT '{0}', '{1}', '{2}', '{3}', '{4}' FROM DUAL ";
int count = 0;
try
{
connexion.Open();
var batch = new StringBuilder();
foreach (var c in clients)
{
batch.Append(string.Format(sql, c.Agence, c.Code, c.Siret, c.Type));
count++;
if ((count % 500) == 0)
{
connexion.Execute(Sql_FromSelect(batch));
batch = new StringBuilder();
}
}
connexion.Execute(Sql_FromSelect(batch));
}
catch (Exception ex)
{
throw ex;
}
finally
{
connexion.Close();
}
return count;
}
private string Sql_FromSelect(StringBuilder batch)
{
// Au départ :
// "UNION SELECT '...', '...', '...', '...', '...' FROM DUAL UNION SELECT ... "
batch.Remove(0, 5);
// => " SELECT '...', '...', '...', '...', '...' FROM DUAL UNION SELECT ... "
var start = @"BEGIN INSERT INTO Clients (Agence, Code, Siret, Type) ";
batch.Insert(0, start);
// => "BEGIN INSERT INTO Clients (...) SELECT '...', '...', ... "
batch.Append("; END;");
// => "BEGIN INSERT INTO Clients (...) SELECT ... FROM DUAL; END;"
return batch.ToString();
}
Mise à jour : Pour les plus curieux, les sources du projet qui m'a servi pour tester tout ça sont désormais sur GitHub.
English version: Optimize multiple INSERTs (for Oracle).