SuperDo : Une todo liste avec Sinatra et DataMapper
2010-09-02 #ruby#sinatra
Ceci est la traduction du tutoriel "SuperDo - A Sinatra and DataMapper To Do List" de Darren Jones.
Dans ce nouveau tutoriel dédié à Sinatra, Darren explique comment construire une petite application de type Todo liste qui utilisera une base de données pour enregistrer les différentes tâches. Cela donnera l'occasion d'aborder les points suivants :
- Installer SQLIte et DataMapper
- Se connecter à la base de données
- Gérer les actions de types CRUD
- Utiliser des URLs de type RESTFul
Avant de commencer, il est bien entendu nécessaire d'avoir procédé à l'installation de Ruby, de Ruby Gems et de Sinatra.
L'application que nous allons développer s'appellera Superdo et nous pouvons d'ores et déjà voir ce qu'elle donnera sur la version que Darren à déployé sur Heroku.
Installer SQLite et Datamapper
Dans ce tutoriel, nous allons utiliser SQLite comme base de données et DataMapper comme ORM pour nous connecter à notre base de données.
Nous devons donc commencer par installer SQLite sous Windows 7 en téléchargeant la version la plus récente de sqlite3.dll depuis le site de SQLite, soit sqlitedll-3_6_23_1.zip à ce jour. Après avoir décompacté cette archive, il ne reste qu'à copier le fichier sqlite3.dll dans le répertoire C:\Ruby\bin.
Puis il faut installer le gem qui permet la prise en charge de SQLite par Ruby :
C:\Ruby>gem install sqlite3-ruby --no-rdoc --no-ri
Ce qui donne le résultat suivant :
=============================================================================
You've installed the binary version of sqlite3-ruby.
It was built using SQLite3 version 3.6.23.1.
It's recommended to use the exact same version to avoid potential issues.
At the time of building this gem, the necessary DLL files where available
in the following download:
http://www.sqlite.org/sqlitedll-3_6_23_1.zip
You can put the sqlite3.dll available in this package in your Ruby bin
directory, for example C:\Ruby\bin
=============================================================================
Successfully installed sqlite3-ruby-1.3.1-x86-mingw32
1 gem installed
Note : Les paramètres --no-rdoc --no-ri
ont permis d'éviter d'installer la documentation en local.
On installe ensuite le gem Datamapper :
C:\Ruby>gem install data_mapper --no-rdoc --no-ri
Ce qui donne :
Successfully installed extlib-0.9.15
Successfully installed addressable-2.2.0
Successfully installed dm-core-1.0.2
Successfully installed dm-aggregates-1.0.2
Successfully installed dm-migrations-1.0.2
Successfully installed dm-constraints-1.0.2
Successfully installed dm-transactions-1.0.2
Successfully installed fastercsv-1.5.3
Successfully installed json_pure-1.4.6
Successfully installed dm-serializer-1.0.2
Successfully installed dm-timestamps-1.0.2
Successfully installed dm-validations-1.0.2
Successfully installed uuidtools-2.1.1
Successfully installed stringex-1.1.0
Successfully installed dm-types-1.0.2
Successfully installed data_mapper-1.0.2
16 gems installed
Et il ne reste plus qu'à installer l'adaptateur SQLite pour que Datamapper puisse gérer les bases de données SQLite :
C:\Ruby>gem install dm-sqlite-adapter --no-rdoc --no-ri
Ce qui donne :
=============================================================================
You've installed the binary version of do_sqlite3.
It was built using Sqlite3 version 3_6_23_1.
It's recommended to use the exact same version to avoid potential issues.
At the time of building this gem, the necessary DLL files where available
in the following download:
http://www.sqlite.org/sqlitedll-3_6_23_1.zip
You can put the sqlite3.dll available in this package in your Ruby bin
directory, for example C:\Ruby\bin
=============================================================================
Successfully installed data_objects-0.10.2
Successfully installed do_sqlite3-0.10.2-x86-mingw32
Successfully installed dm-do-adapter-1.0.2
Successfully installed dm-sqlite-adapter-1.0.2
4 gems installed
Après cela, tout est en place pour pouvoir développer une application web avec du contenu dynamique.
Se connecter à la base de données
La première chose à faire est de créer un répertoire nommé "todo" pour notre application et de commencer par y enregistrer un fichier "main.rb" avec le code ci-dessous :
require 'rubygems'
require 'sinatra'
require 'dm-core'
require 'dm-migrations'
DataMapper.setup(:default, ENV['DATABASE_URL'] || "sqlite3://#{Dir.pwd}/development.db")
class Task
include DataMapper::Resource
property :id, Serial
property :name, String
property :completed_at, DateTime
end
DataMapper.auto_upgrade!
Ça fait pas mal de nouveaux trucs d'un coup, aussi je vais les expliquer un par un.
Les 4 premières lignes déclarent les gems nécessaires :
require 'rubygems'
require 'sinatra'
require 'dm-core'
require 'dm-migrations'
On a besoin de "rubygems" et de "sinatra" pour toutes les applications Sinatra et le gem "dm-core" est nécessaire pour DataMapper. Par rapport au tutoriel de Darren, on a besoin en plus du gem "dm-migrations" car il n'est plus intégré à "dm_core" depuis le passage en version 1.00 de DataMapper.
Le morceau de code suivant permet de se connecter à la base de données :
DataMapper.setup(:default, ENV['DATABASE_URL'] || "sqlite3://#{Dir.pwd}/development.db")
Voila un bout de code très intéressant qui vaut le coup d'être conservé. Il commence par tester si l'application est déployée sur Heroku et dans ce cas se connecte à la base de données qui y est hébergée. Dans le cas contraire, il se connecte à une base de données SQLite locale nommée "development.db". Si celle-ci n'existe pas encore, SQLite la crée automatiquement.
Le bloc de code suivant créé une classe Task avec ses propriétés :
class Task
include DataMapper::Resource
property :id, Serial
property :name, String
property :completed_at, DateTime
end
Vous aurez besoin de la ligne de code include DataMapper::Resource dans toutes les classes qui utilisent DataMapper.
Puis les 3 lignes suivantes définissent les propriétés de votre classe Task. La
première défini un identifiant unique propre à chaque tâche. Le type
Serial qui lui est associé indique que la propriété "id" doit être
auto-incrémentée à chaque fois qu'une nouvelle tâche est ajoutée à la base de
données. La deuxième propriété "name" va servir à un libellé pour chaque tâche
et nous indiquons à DataMapper que celui-ci sera de type String.
Et enfin, la dernière propriété "completed_at" est définie en tant que
DateTime pour enregistrer à quel moment la tâche a été marquée
comme terminée. Cette propriété nous permettra également de savoir si la tâche
a été réalisée ou non : une tâche dont la propriété "completed_at" sera à
nil étant considérée comme à faire.
La dernière ligne du fichier "main.rb" contient l'appel à la méthode auto_upgrade! :
DataMapper.auto_upgrade!
Cette méthode indique à DataMapper de mettre à jour la base de données pour
refléter toutes modifications apportées à la classe Task. Grâce à cela, nous
pouvons ajouter ou supprimer des propriétés à la classe Task et DataMapper se
chargera de répercuter ces modifications dans la base de données. Cela permet
de développer très rapidement et nous évite de mettre les mains dans le
cambouis pour essayer de faire évoluer la structure de notre base de données.
La commande auto_upgrade! a l'avantage de conserver les données
existantes dans la base de données. Si vous préférez repartir d'une base de
données vide, vous pouvez choisir d'utiliser la commande
DataMapper.auto_migrate! qui efface définitivement toutes les
données déjà présentes dans la base de données.
OK. Maintenant que la base de données est configurée, nous allons pouvoir la tester. Comme nous n'avons pas encore d'interface web, nous allons ouvrir une invite de commandes et aller dans le répertoire "todo" pour lancer la commande suivante :
C:\Ruby\projets\todo>irb -r main.rb
Cela a pour effet d'ouvrir un shell "irb", mais étant donné que nous avons ajouté l'option "-r main.rb", tout le code de notre fichier "main.rb" est chargé dans notre session. Par conséquent, nous avons accès à la base de données et pouvons créer, rechercher ou supprimer des tâches.
Pour commencer, examinons la liste de nos tâches :
irb(main):001:0> Task.all
=> []
Cette commande renvoie à juste titre un tableau vide puisque pour l'instant nous n'avons encore aucune tâche dans notre base de données. On va donc en créer une nouvelle :
irb(main):002:0> t = Task.new
=> #<Task @id=nil @name=nil @completed_at=nil>
irb(main):003:0> t.name = "Acheter du lait"
=> "Get milk"
Pour l'instant, cette tâche n'existe qu'en mémoire. Nous devons explicitement l'enregistrer dans la base de données :
irb(main):004:0> t.save
=> true
Vérifions que cela a correctement fonctionné en recherchant maintenant la première tâche :
irb(main):005:0> Task.first
=> #<Task @id=1 @name="Acheter du lait" @completed_at=nil>
Il existe une autre façon pour créer une nouvelle tâche, en utilisant la
commande create :
irb(main):006:0> Task.create(:name => "Acheter des bananes")
=> #<Task @id=2 @name="Acheter des bananes" @completed_at=<not loaded>>
Nous pouvons ajouter des paramètres en les plaçant entre parenthèses après
le nom de méthode et en utilisant la notation hash du langage Ruby. Avec la
commande create, il n'est pas nécessaire d'enregistrer nous même
la nouvelle tâche, car elle est automatiquement sauvegardée dans la base de
données. Nous pouvons vérifier cela en demandant à afficher toutes les tâches
de la table Tasks :
irb(main):007:0> Task.all
=> [#<Task @id=1 @name="Acheter du lait" @completed_at=nil>, #<Task @id=2 @name=
"Acheter des bananes" @completed_at=nil>]
Comme vous le constatez, nos deux tâches apparaissent désormais dans le
tableau. Mais ça risque de devenir un peu compliqué pour s'y retrouver parmi
toutes les tâches dès lors qu'on aura un grand nombre d'enregistrement. C'est
pourquoi nous pouvons plus simplement utiliser la méthode
count :
irb(main):008:0> Task.all.count
=> 2
Cela nous indique qu'il y a actuellement 2 tâches enregistrées dans la base de données.
Nous avons donc vu comment créer et rechercher des enregistrements dans notre base de données. Nous allons à présent voir comment les modifier. Supposons que nous préférions le lait demi-écrémé. Nous devons tout d'abord retrouver le bon enregistrement :
irb(main):009:0> t = Task.first(:name => "Acheter du lait")
=> #<Task @id=1 @name="Acheter du lait" @completed_at=nil>
Il s'agit là d'une des façons de retrouver des enregistrements dans une base de données. Dans notre cas, nous voulons retrouver la tâche dont la propriété "name" contient "Acheter du lait" pour la charger dans la variable t. Nous avons alors deux méthodes pour modifier cet enregistrement. La première consiste à modifier manuellement la variable t puis à la sauvegarder :
irb(main):010:0> t.name = "Acheter du lait demi-écrémé"
=> "Acheter du lait demi-écrémé"
irb(main):011:0> t.save
=> true
irb(main):012:0> t
=> #<Task @id=1 @name="Acheter du lait demi-écrémé" @completed_at=nil>
La seconde méthode est d'utiliser la méthode update. Disons que
finallement nous voulons du lait entier :
irb(main):013:0> t.update(:name => "Acheter du lait entier")
=> true
irb(main):014:0> t
=> #<Task @id=1 @name="Acheter du lait entier" @completed_at=nil>
Et pour finir, voyons comment gérer la dernière des actions CRUD : la
suppression. Disons que nous n'avons pas besoin de lait ce qui fait que nous
pouvons supprimer cette tâche. On commence donc par retrouver cette tâche puis
nous la supprimons à l'aide de la commande destroy :
irb(main):015:0> t = Task.get(1)
=> #<Task @id=1 @name="Acheter du lait entier" @completed_at=nil>
irb(main):016:0> t.destroy
=> true
Cette fois-ci, j'ai employé la méthode get pour retrouver la
tâche dont l'identifiant est 1. Cette syntaxe n'est utilisable que lorsque l'on
passe par la clé primaire pour effectuer la recherche. Dans notre cas, la clé
primaire est la propriété id dont la valeur est 1 pour la tâche recherchée.
Nous aurons souvent recours à cette méthode par la suite pour retrouver les
tâches à partir d'URLs uniques. Nous pouvons désormais vérifier que la tâche a
bien été supprimée en redemandant la liste de toutes les tâches :
irb(main):017:0> Task.all
=> [#<Task @id=2 @name="Acheter des bananes" @completed_at=nil>]
Nous constatons alors que seule la tâche "Acheter des bananes" reste enregistrée dans notre base de données.
C'était plutôt amusant et le fait d'utiliser la console constitue une excellente entrée en matière pour faire des essais et tester notre base de données. Mais notre objectif étant de créer une application internet, il est temps de développer une interface pour toutes ces actions.
Associer des URLs RESTful aux actions CRUD
L'interface web que nous allons créer pour interagir avec notre base de données suivra une architecture REST. Cela consiste à utiliser les verbes http POST, GET, PUT et DELETE. Ceux-ci sont très similaires aux actions CRUD (Create, Read, Update et Delete) destinées à mettre à jour la base de données. Chaque tâche aura sa propre URL de la forme "/tasks/:id" où ":id" correspond à l'identifiant unique de la tâche. Par exemple, la tâche "Acheter des bananes" que nous avons créée auparavant aurait l'URL "/tasks/2" étant donné que son identifiant est 2. Le fait qu'il faille lire, modifier ou supprimer une tâche dépendra du verbe http que le navigateur enverra. Par conséquent, même si l'URL sera toujours la même, l'action effectuée sera différente. Et chacune de ces actions sera traitée par un handler différent dans notre application Sinatra.
Commençons par créer le handler qui va servir à consulter les tâches. Pour cela, nous devons modifier le code du fichier "main.rb" de la façon suivante :
require 'rubygems'
require 'sinatra'
require 'dm-core'
require 'dm-migrations'
DataMapper.setup(:default, ENV['DATABASE_URL'] || "sqlite3://#{Dir.pwd}/development.db")
class Task
include DataMapper::Resource
property :id, Serial
property :name, String
property :completed_at, DateTime
end
# Afficher une tâche
get '/task/:id' do
@task = Task.get(params[:id])
erb :task
end
DataMapper.auto_upgrade!
Le handler qui sert à afficher une tâche est contenu dans le code ci-dessous :
# Afficher une tâche
get '/task/:id' do
@task = Task.get(params[:id])
erb :task
end
Ce code recherche la tâche dont l'identifiant est égal au paramètre "id" mentionné dans l'URL et affecte cette tâche à la variable d'instance @task qui pourra être utilisée au niveau de la vue. Nous demandons ensuite à Sinatra d'afficher la vue "task" à l'aide d'erb. Il nous faut donc créer une vue "task.erb" dans le dossier "views" contenant les vues de notre application et y saisir le code ci-dessous :
<h2><%= @task.name %></h2>
Il n'y a là rien d'extraordinaire. Juste un titre pour afficher le libellé de la tâche. Pendant que nous y sommes, nous allons créer le layout de notre application. Pour cela, nous créons un fichier "layout.erb" dans le même répertoire "views" avec le code suivant :
<!DOCTYPE html>
<html lang="fr">
<head>
<title>To Do Liste</title>
<meta charset=windows-1250 />
</head>
<body>
<h1>To Do Liste</h1>
<%= yield %>
</body>
</html>
Là encore, rien de bien spécial. Nous nous contentons d'un code HTML très basique avec un simple titre annonçant "To Do Liste". On sauvegarde et on va pouvoir tester tout ça en lançant le serveur :
C:\Ruby\projets\todo>ruby main.rb
Nous pouvons alors utiliser notre navigateur pour consulter l'URL "http://localhost:4567/task/2" et on obtient l'écran suivant :
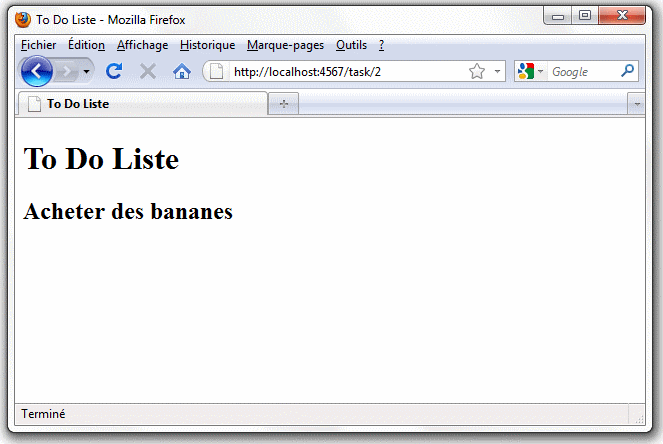
Créer de nouvelles tâches
Passons maintenant à la création d'une nouvelle tâche par l'intermédiaire d'un formulaire web. La façon standard de faire ça est de découper l'action de création en deux handlers :
- le premier est nommé "new" et sert à afficher un formulaire de saisie
- le second est nommé "create" et sert pour créer la nouvelle tâche à partir des données saisies (généralement en arrière plan)
Commençons par l'action "new" et son formulaire. Le code de l'action est très simple puisque nous souhaitons seulement afficher un formulaire de saisie lorsque l'utilisateur consulte l'URL "/task/new". Pour réaliser cela, copiez le code ci-dessous avant le code pour l'action "show" (sans quoi il ne serait pas pris en compte) :
# Saisir une nouvelle tâche
get '/task/new' do
erb :new
end
Ce code se contente d'afficher la vue "new.erb" que nous allons immédiatement créer dans le dossier "views" en saisisant les quelques lignes suivantes :
<form action="/task/create" method="POST">
<input type="text" name="name" id="name">
<input type="submit" value="Ajouter la tâche"/>
</form>
C'est un formulaire simple qui permet à l'utilisateur de saisir le libellé d'une nouvelle tâche dans une zone de saisie nommée "name" (ce qui correspond à la colonne "name" de la table des tâches, ce qui n'est pas obligatoire mais beaucoup plus facile).
Le bouton submit va envoyer cette information vers l'URL "/task/create" pour laquelle nous allons créer le handler correspondant. Son code est un peu plus compliqué que celui de l'action "new", mais pas tant que ça :
# Créer une nouvelle tâche
post '/task/create' do
task = Task.new(:name => params[:name])
if task.save
status 201
redirect '/task/' + task.id.to_s
else
status 412
redirect '/tasks'
end
end
Examinons d'un peu plus près ce qui se passe dans ce code. Pour commencer, il s'exécute lorsqu'il s'agit d'une requête POST étant donné que nous attendons les données postées depuis le formulaire. Puis il crée une nouvelle tâche en lui donnant comme nom la valeur stockée dans le paramètre "name" en provenance du formulaire. Ensuite nous vérifions que la tâche a bien été enregistrée. Si c'est le cas, nous définissons le statut http à 201 (la valeur standard pour signifier que quelque chose a été créé) et renvoyons l'utilisateur vers l'URL affichant la tâche en concaténant son identifiant après "/task/" (ce qui correspond à l'action d'affichage d'une tâche que nous avions développée auparavant). Dans le cas où la tâche n'a pas été sauvegardée, nous renvoyons un statut http à 412 ce qui indique au navigateur que certaines conditions (comme la validation de données) n'ont pas été remplies. L'utilisateur est alors redirigé vers la page d'index "/tasks" (que nous n'avons pas encore créé mais dont nous nous occuperons très bientôt).
Nous pouvons alors tester tout cela et créer une nouvelle tâche à l'aide du navigateur en allant à l'URL "http://localhost:4567/task/new" qui nous présente le formulaire de saisie reproduit ci-dessous :
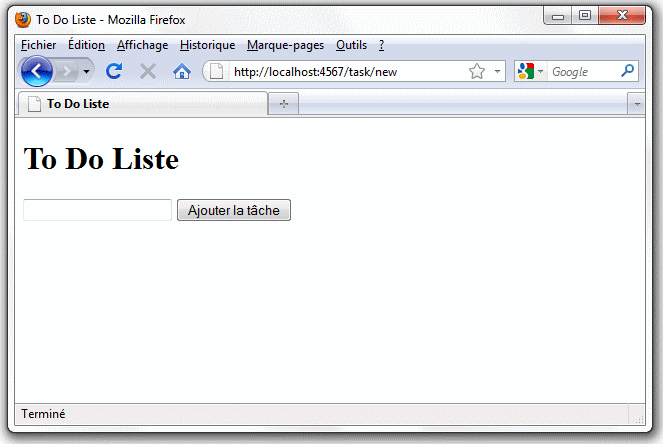
Continuez et ajoutez plusieurs nouvelles tâches. À chaque fois que vous validez le formulaire, vous devez voir apparaitre une nouvelle page qui affiche le nom de la nouvelle tâche créée.
Arrivé à ce point, le contenu de votre fichier "main.rb" doit être le suivant :
require 'rubygems'
require 'sinatra'
require 'dm-core'
require 'dm-migrations'
DataMapper.setup(:default, ENV['DATABASE_URL'] || "sqlite3://#{Dir.pwd}/development.db")
class Task
include DataMapper::Resource
property :id, Serial
property :name, String
property :completed_at, DateTime
end
# Saisir une nouvelle tâche
get '/task/new' do
erb :new
end
# Créer une nouvelle tâche
post '/task/create' do
task = Task.new(:name => params[:name])
if task.save
status 201
redirect '/task/' + task.id.to_s
else
status 412
redirect '/tasks'
end
end
# Afficher une tâche
get '/task/:id' do
@task = Task.get(params[:id])
erb :task
end
DataMapper.auto_upgrade!
Afficher la liste des tâches
Pour l'instant, nous pouvons créer de nouvelles tâches et les afficher une par une. Nous allons maintenant afficher une liste qui contiendra toutes les tâches existantes. Pour cela, nous commençons par créer l'action suivante :
# Afficher toutes les tâches
get '/tasks' do
@tasks = Task.all
erb :index
end
Ce code récupère tout simplement la liste de toutes les tâches enregistrées dans la base de données via la méthode "all" et les stocke dans la variable d'instance "@tasks" qui sera utilisable dans la vue. Puis il affiche la vue "index.erb" que nous allons créer dans le sous-répertoire "views" :
<h2>Liste des tâches :</h2>
<% unless @tasks.empty? %>
<ul>
<% @tasks.each do |task| %>
<li <%= "class=\"completed\"" if task.completed_at %>>
<a href="/task/<%=task.id%>"><%= task.name %></a>
</li>
<% end %>
</ul>
<% else %>
<p>Aucune tâche enregistrée !</p>
<% end %>
Cette vue commence par tester si le tableau des tâches est vide. Si ce n'est pas le cas, elle parcours ce tableau pour créer une liste à puces à partir des tâches qu'il contient. Pour chaque tâche, elle teste si celle-ci a été terminée ou non et ajoute une classe "completed" lorsque c'est le cas. Cela nous servira plus tard lorsque nous travaillerons sur la feuille de style de notre application. Dans le cas où le tableau "@tasks" est vide, nous affichons simplement un message pour indiquer qu'il n'y a pas de tâche. Si vous lancez votre navigateur pour visiter l'URL "http://localhost:4567/tasks", vous obtenez l'écran suivant :
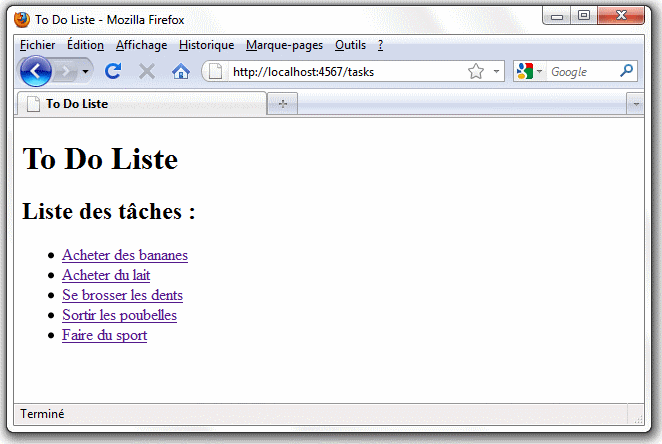
Modifier des tâches
Il ne nous reste plus que quelques traitements à gérer, à savoir la modification et la suppression. Nous allons pour l'instant permettre aux utilisateurs de modifier les tâches existantes. Comme pour la création avec les actions "new" et "create", la modification nécessite une action "edit" associée avec une action "update". L'action "edit" affiche un formulaire qui permet à l'utilisateur de saisir les informations d'une tâche et de valider. C'est l'action "update" qui effectue la mise à jour dans la base de données. Voici ce que donne ces deux actions dans le code ci-dessous :
# Modifier une tâche existante
get '/task/:id/edit' do
@task = Task.get(params[:id])
erb :edit
end
# Mettre à jour une tâche
put '/task/:id' do
task = Task.get(params[:id])
task.completed_at = params[:completed] ? Time.now : nil
task.name = (params[:name])
if task.save
status 201
redirect '/task/' + task.id.to_s
else
status 412
redirect '/tasks'
end
end
Nous devons également créer un fichier "edit.erb" dans le sous-répertoire des vues :
<form action="/task/<%= @task.id %>" method="post">
<input name="_method" type="hidden" value="put" />
<input type="text" name="name" id="name" value="<%= @task.name %>">
<input id="completed" name="completed" type="checkbox" value="done" <%= @task.completed_at ? "checked" : "" %>/>
<input id="task_submit" name="commit" type="submit" value="Modifier" />
</form>
Il y a pas mal de trucs à voir là dedans. Pour commencer, le handler "edit" se contente d'afficher un formulaire lorsque l'utilisateur accède à l'URL "task/2/edit". Le formulaire est assez semblable à celui pour créer une nouvelle tâche, à quelques différences près. Il contient un champ pour le nom qui est pré-rempli avec le libellé de la tâche, une case à cocher si on veut signaler que la tâche est terminée et un bouton pour envoyer les données saisies.
La particularité de ce formulaire est qu'il poste ses données vers l'URL
"task/2", soit la même URL que celle que nous utilisons déjà pour afficher une
tâche. C'est pourquoi on défini un champ caché avec la ligne <input name="_method" type="hidden" value="put" /> pour indiquer qu'il
s'agit en fait d'une requête http PUT et pas d'une simple requête POST. Cet
artifice est nécessaire parce qu'à l'heure actuelle, il n'existe aucun
navigateur qui sache gérer les requêtes PUT. Cela a pour effet d'envoyer la
requête sous forme de POST mais Sinatra voyant qu'il y a un champ caché
"_method" avec la valeur "put", il agit comme s'il avait reçu une requête http
PUT et la transmet au handler pour l'URL "task/2/edit" qui correspond à un PUT,
soit la méthode "update" dans notre code.
Le handler "update" est assez proche du handler "create". Il commence par accéder à la base de données pour retrouver la tâche à modifier en utilisant l'id stocké dans la collection "params" (notez au passage que celui-ci provient de l'URL et pas du formulaire). Il vérifie ensuite si la case à cocher a été cochée et si c'est le cas il initialise la propriété "completed_at" avec l'heure en cours, pour indiquer que la tâche est terminée. Dans le cas contraire, il affecte simplement la valeur nil à cette propriété. Puis après avoir mis à jour la propriété "name", la tâche est enregistrée en suivant la même méthode qu'au niveau du handler "create".
Testons tout ça. Supposons qu'armé de courage je décide de vraiment faire du sport et plus particulièrement du vélo. Je vais donc cliquer sur le lien "Faire du sport" dans la liste des tâches puis ajouter "/edit" à la fin de l'URL de la page obtenue (c'est pas très ergonomique mais on s'occupera de ça plus tard). Cela a pour effet d'afficher le formulaire de mise à jour de la tâche où je vais pouvoir modifier le nom en "Faire du velo" puis cliquer sur le bouton "Modifier" pour enregistrer la modification.
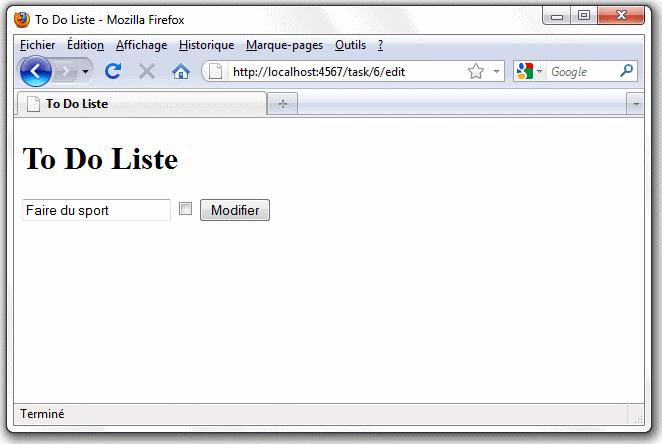
Supprimer des tâches.
Le dernier traitement à prendre en compte est la suppression de tâches existantes. Nous allons faire cela en deux étapes. En premier lieu, nous allons ajouter un lien pour la suppression dans la vue "edit". Pour cela, nous ouvrons le fichier "edit.erb" pour le modifier comme ci-dessous :
<form action="/task/<%= @task.id %>" method="post">
<input name="_method" type="hidden" value="put" />
<input type="text" name="name" id="name" value="<%= @task.name %>">
<input id="completed" name="completed" type="checkbox" value="done" <%= @task.completed_at ? "checked" : "" %>/>
<input id="task_submit" name="commit" type="submit" value="Modifier" />
</form>
<p><a href="/task/<%= @task.id %>/delete">Supprimer cette tâche</a></p>
La dernière ligne dans ce code ajoute un lien vers l'URL "/task/:id/delete" qui va conduire vers une page où nous demanderons à l'utilisateur s'il est certain de vouloir supprimer la tâche. Nous allons donc ajouter le traitement pour faire confirmer la suppression à notre fichier "main.rb" :
# Confirmer la suppression
get '/task/:id/delete' do
@task = Task.get(params[:id])
erb :delete
end
Ce code recherche la tâche dont l'identifiant est mentionné dans l'URL puis stocke cette tâche dans la variable d'instance "@task". Encore une fois, nous devons utiliser une variable d'instance (qui est préfixée par un @) car nous aurons besoin d'y faire référence dans la vue de confirmation. Et maintenant, il nous reste à coder cet écran de confirmation en créant un fichier "delete.erb" dans le sous-répertoire des vues et en y saisissant le code ci-dessous :
<h2><%= @task.name %><h2>
<h3>Est-ce que vous souhaitez réellement supprimer cette tâche ?</h3>
<form action="/task/<%= @task.id %>" method="post">
<input type="hidden" name="_method" value="delete" />
<input type="submit" value="Supprimer"> ou <a href="/tasks">Annuler</a>
</form>
Le fonctionnement de cette vue est très proche du formulaire pour la modification. Vous pouvez voir que là aussi nous avons besoin d'un champ caché pour simuler la méthode http DELETE étant donné que quasiment aucun navigateur ne sait la gérer. Et nous avons en plus ajouté un lien pour annuler la demande de suppression et revenir à la liste des tâches.
Il ne nous reste donc plus qu'à créer le code pour gérer l'action qui va réellement supprimer la tâche dans la base de données. Pour cela, nous devons ajouter le code suivant à notre fichier "main.rb" :
# Supprimer une tâche
delete '/task/:id' do
Task.get(params[:id]).destroy
redirect '/tasks'
end
Nous pouvons alors tester ce code en supprimant la tâche "Faire du vélo" (de toute façon je n'ai pas de vélo). On clique sur cette tâche dans la liste des tâches, on ajoute "/edit" à la fin de l'URL obtenue puis là on suit le lien "Supprimer la tâche" ce qui nous amène sur l'écran de confirmation ci-dessous :
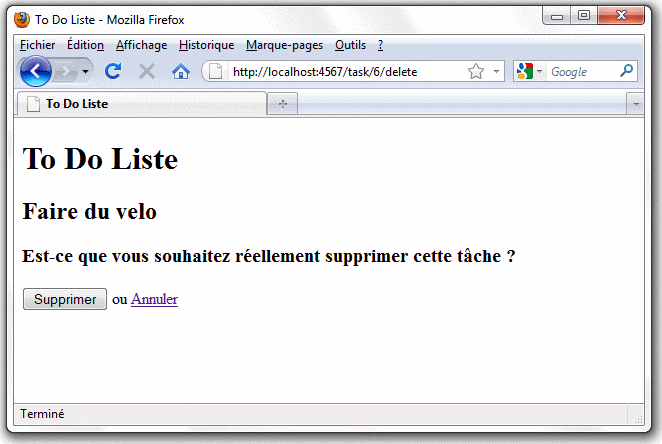
Ces deux derniers traitements sont une excellente illustration de la façon dont REST fonctionne. Les actions pour afficher, modifier et supprimer une tâche correspondent toutes à la même URL (par exemple "/task/2") et concernent le même objet (la tâche dont l'identifiant est 2 dans notre exemple). Mais elles accomplissent toutes des fonctions très différentes et elles sont sélectionnées en fonction du verbe http employé (soit GET, UPDATE et DELETE respectivement).
Le code source du fichier "main.rb" complet présente désormais le contenu suivant :
require 'rubygems'
require 'sinatra'
require 'dm-core'
require 'dm-migrations'
DataMapper.setup(:default, ENV['DATABASE_URL'] || "sqlite3://#{Dir.pwd}/development.db")
class Task
include DataMapper::Resource
property :id, Serial
property :name, String
property :completed_at, DateTime
end
# Saisir une nouvelle tâche
get '/task/new' do
erb :new
end
# Créer une nouvelle tâche
post '/task/create' do
task = Task.new(:name => params[:name])
if task.save
status 201
redirect '/task/' + task.id.to_s
else
status 412
redirect '/tasks'
end
end
# Modifier une tâche existante
get '/task/:id/edit' do
@task = Task.get(params[:id])
erb :edit
end
# Mettre à jour une tâche
put '/task/:id' do
task = Task.get(params[:id])
task.completed_at = params[:completed] ? Time.now : nil
task.name = (params[:name])
if task.save
status 201
redirect '/task/' + task.id.to_s
else
status 412
redirect '/tasks'
end
end
# Confirmer la suppression
get '/task/:id/delete' do
@task = Task.get(params[:id])
erb :delete
end
# Supprimer une tâche
delete '/task/:id' do
Task.get(params[:id]).destroy
redirect '/tasks'
end
# Afficher une tâche
get '/task/:id' do
@task = Task.get(params[:id])
erb :task
end
# Afficher toutes les tâches
get '/tasks' do
@tasks = Task.all
erb :index
end
DataMapper.auto_upgrade!
Celui-ci contient à présent les 7 handlers REST traditionnels : index, show, new, create, edit, update et delete ainsi qu'une action supplémentaire pour faire confirmer la suppression.
Améliorer l'interface utilisateur
Notre application est maintenant complète, mais il reste encore quelques points où pouvons encore l'améliorer. Comme je l'ai indiqué auparavant, son code suit les conventions de Rails en ce qui concerne les URLs REST. Ce qui est bien avec Sinatra, c'est que vous pouvez faire les choses à votre façon. C'est pourquoi je vais maintenant modifier certaines de ces URLs.
Pour commencer, je préfèrerais que ce soit la page principale qui affiche la liste de toutes les tâches plutôt que d'avoir une URL "/tasks" pour cela. Cette modification est toute simple à faire :
# Afficher toutes les tâches
get '/' do
@tasks = Task.all
erb :index
end
J'aimerais aussi que le formulaire pour créer une nouvelle tâche apparaisse dans la page principale, à la suite de la liste des tâches. Pour cela, il suffit de copier le code du fichier "new.erb" dans le fichier "index.erb" (tous deux dans le sous-répertoire views). Le fichier "index.erb" contient alors le code suivant :
<h2>Liste des tâches :</h2>
<% unless @tasks.empty? %>
<ul>
<% @tasks.each do |task| %>
<li <%= "class=\"completed\"" if task.completed_at %>>
<a href="/task/<%=task.id%>"><%= task.name %></a>
</li>
<% end %>
</ul>
<% else %>
<p>Aucune tâche enregistrée !</p>
<% end %>
<h2>Créer une tâche</h2>
<form action="/task/create" method="POST">
<input type="text" name="name" id="name">
<input type="submit" value="Ajouter la tâche"/>
</form>
Il est ensuite possible de supprimer le fichier new.erb qui ne sert plus à rien ainsi que le handler pour l'action "new" dans le fichier "main.rb" (par contre, il faut conserver celui pour l'action "create"). Je vais également supprimer l'action "show" et la vue "task.erb" qui lui est associée étant donné que cela ne sert qu'à afficher le nom d'une tâche, ce que l'on peut déjà voir dans la liste des tâches. L'avantage de cette suppression, c'est que l'URL "/task/:id" ne sert plus et que je vais pouvoir l'utiliser pour afficher le formulaire de mise à jour d'une tâche. Pour cela, il faut donc modifier l'action "edit" comme suit :
# Modifier une tâche existante
get '/task/:id' do
@task = Task.get(params[:id])
erb :edit
end
Votre code fait tout de suite plus propre. Il reste encore quelques redirections qui pointent vers des URLs qui n'existent plus et qu'il faut donc corriger, généralement pour les faire pointer vers la racine du site. Suite à tout cela, le code du fichier "main.erb" est beaucoup plus léger et doit ressembler à ceci :
require 'rubygems'
require 'sinatra'
require 'dm-core'
require 'dm-migrations'
DataMapper.setup(:default, ENV['DATABASE_URL'] || "sqlite3://#{Dir.pwd}/development.db")
class Task
include DataMapper::Resource
property :id, Serial
property :name, String
property :completed_at, DateTime
end
# Créer une nouvelle tâche
post '/task/create' do
task = Task.new(:name => params[:name])
if task.save
status 201
redirect '/'
else
status 412
redirect '/'
end
end
# Modifier une tâche existante
get '/task/:id' do
@task = Task.get(params[:id])
erb :edit
end
# Mettre à jour une tâche
put '/task/:id' do
task = Task.get(params[:id])
task.completed_at = params[:completed] ? Time.now : nil
task.name = (params[:name])
if task.save
status 201
redirect '/'
else
status 412
redirect '/'
end
end
# Confirmer la suppression
get '/task/:id/delete' do
@task = Task.get(params[:id])
erb :delete
end
# Supprimer une tâche
delete '/task/:id' do
Task.get(params[:id]).destroy
redirect '/'
end
# Afficher toutes les tâches
get '/' do
@tasks = Task.all
erb :index
end
DataMapper.auto_upgrade!
J'ai aussi décidé d'ajouter un lien de retour vers la page d'accueil quand on clique sur le titre de la page. Pour que ce lien apparaisse partout, il faut modifier le fichier "layout.erb" dans le sous-répertoire des vues :
<!DOCTYPE html>
<html lang="fr">
<head>
<title>To Do Liste</title>
<meta charset=windows-1250 />
</head>
<body>
<h1><a href="/">To Do Liste</a></h1>
<%= yield %>
</body>
</html>
L'application est désormais plus simple à utiliser et fonctionne de façon beaucoup plus intuitive :
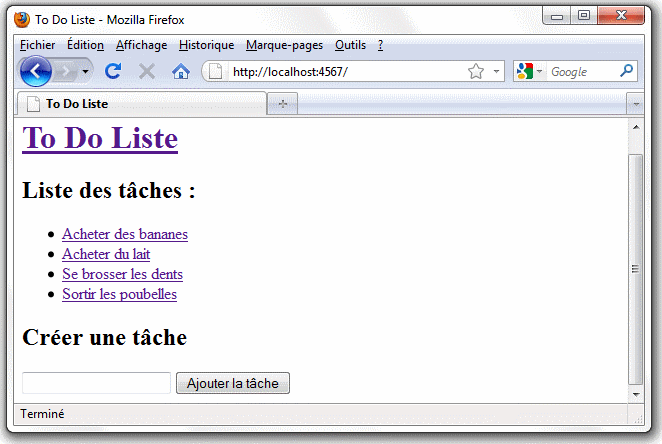
Améliorer le code
Après ces modifications visibles par l'utilisateur, je vais réaliser quelques modifications destinées à simplifier le code de l'application. Pour commencer, je vais ajouter quelques méthodes pour faciliter la gestion des tâches terminées. Étant donné qu'il s'agit de méthodes liées aux tâches, il faut les placer dans la définition de la classe :
class Task
include DataMapper::Resource
property :id, Serial
property :name, String
property :completed_at, DateTime
def completed?
true if completed_at
end
def self.completed
all(:completed_at.not => nil)
end
end
La première méthode est une méthode d'instance: elle est définie au niveau de la tâche, comme dans le cas d'une propriété. Elle considère que s'il y a une date de définie pour la propriété "completed_at" c'est que la tâche est terminée et renvoie donc "true" dans ce cas, ou "false" dans le cas contraire.
La seconde méthode est une méthode de classe et porte sur toutes les tâches. Elle peut servir pour filtrer vos recherches à l'aide de DataMapper. Par exemple, le fait d'utiliser Task.completed permettra de retrouver toutes les tâches qui sont terminées. Un truc très intéressant avec ces méthodes, c'est qu'elles peuvent être chainées les unes aux autres pour affiner les recherches. Par exemple, s'il existait une méthode de classe nommée "important" qui renvoyait toutes les tâches importantes (c'est pas trop possible pour l'instant, mais on pourrait parfaitement ajouter un tel truc à l'avenir !), alors on pourrait utiliser Task.important.completed pour retrouver toutes les tâches importantes qui sont terminées.
Je souhaiterais aussi avoir une méthode pour générer un lien vers une tâche. Vous sous souvenez peut-être du code assez minable que j'avais utilisé pour générer un tel lien dans la vue "index.erb" :
<a href="/task/<%=task.id%>"><%= task.name %></a>
Cela serait beaucoup plus propre si nous pouvions masquer cette complexité dans une méthode d'instance au niveau de la classe Task :
class Task
include DataMapper::Resource
property :id, Serial
property :name, String
property :completed_at, DateTime
def completed?
true if completed_at
end
def self.completed
all(:completed_at.not => nil)
end
def link
"<a href=\"task/#{self.id}\">#{self.name}</a>"
end
end
La méthode "link" est vraiment toute simple. Elle renvoie une chaine contenant le code html qui fait un lien vers la page de mise à jour d'une tâche. Pour cela, j'ai utilisé l'interpolation de texte qui consiste à placer du code Ruby devant être évalué à l'intérieur de #{}. Et pour faire référence à la tâche concerné par la méthode, j'ai employé le mot-clé "self".
Après cela, nous pouvons simplifier le contenu de la vue "index.erb" pour utiliser ces différents méthodes, ce qui donne le code suivant :
<h2>Liste des tâches :</h2>
<% unless @tasks.empty? %>
<ul>
<% @tasks.each do |task| %>
<li <%= "class=\"completed\"" if task.completed? %>>
<%= task.link %>
</li>
<% end %>
</ul>
<% else %>
<p>Aucune tâche enregistrée !</p>
<% end %>
<h2>Créer une tâche</h2>
<form action="/task/create" method="POST">
<input type="text" name="name" id="name">
<input type="submit" value="Ajouter la tâche"/>
</form>
Notre source est devenu bien plus lisible et par conséquent beaucoup plus facile à maintenir. Pour devenir parfait, il ne nous reste plus qu'à faire ressortir les tâches qui ont été accomplies. Étant donné que celles-ci sont d'ores et déjà marquées d'une classe CSS "completed" (il vous suffit d'afficher le code source de la page pour contrôler ça), on a juste besoin d'ajouter une ligne de CSS dans le fichier "layout.erb" :
<!DOCTYPE html>
<html lang="fr">
<head>
<title>To Do Liste</title>
<meta charset=windows-1250 />
<style>
.completed {text-decoration: line-through;}
</style>
</head>
<body>
<h1><a href="/">To Do Liste</a></h1>
<%= yield %>
</body>
</html>
Après cette ultime fioriture, vous pouvez compléter votre todo liste ou indiquer que certaines tâches sont terminées et avoir un retour visuel direct dans la liste des tâches de l'écran principal. Au final, votre application doit ressembler à la copie d'écran ci-dessous :
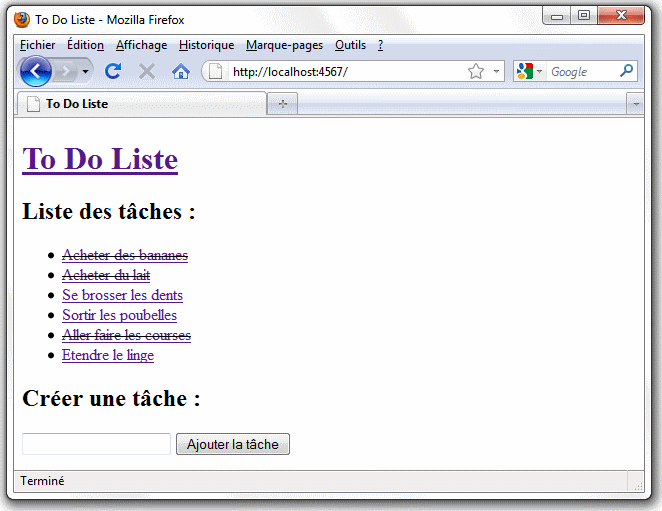
Conclusion
Ce tutoriel correspond à une application de base de données toute simple, mais cela constitue un bon point de départ. Notre application n'est peut être pas tout à fait à la hauteur de son nom étant donné que pour l'instant il faut pas mal chercher pour faire ressortir tout son côté "Super". Mais en nous appuyant sur cette base, nous avons des tas de perspectives d'évolutions. Vous pourriez par exemple essayer de gérer différentes listes de tâches (pour étudier les associations sous DataMapper), vous pourriez ajouter un peu de Javascript ou de jQuery pour améliorer l'interface utilisateur ou encore vous pourriez intégrer une notion de priorité et afficher les tâches prioritaires en haut de liste...